The problem:
When you start small Machine Learning team with a few projects, your experiment is done via Jupyter Notebook and maybe the notebook is in github. The notebook might contain a method to download data so it can be reproducible but it is getting harder and harder to track various experiments.
We also need to make sure models does not train on corrupted / skewed data and only high quality model are pushed to production. Currently these processes are manual and not centralized nor has unified common tool.
How to solve it
Typical ML workflow look like this:
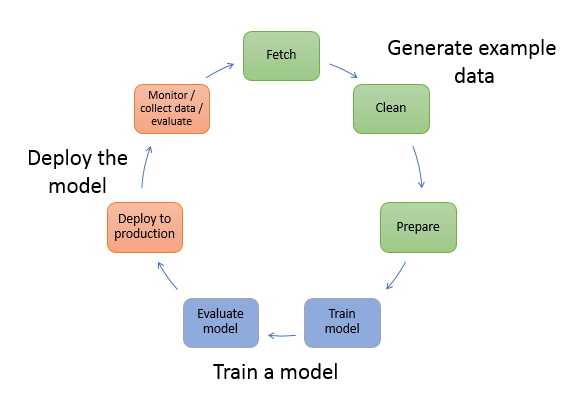
Facebook built FBLearner Flow but it is internal software toolset and not available for public to use. The platform manages:
- Manage data
- Train models
- Evaluate models
- Deploy models
- Make predictions
- Monitor predictions
Google’s TFX is available as 3 components: TensorFlow Transform (data transformation), TensorFlow Model Analysis and TensorFlow Serving. As name indicates, the toolset is narrowed down to TensorFlow. The platform manages:
- Data ingestion
- Data Analysis
- Data Transformation
- Data validation
- Trainer
- Model Evaluation and validation
- Serving
- Logging –> Data ingestion
Uber built michelangelo but just like FBLearner this is is an internal ML-as-a-service platform and not available for public.
At Databricks, a creator of Spark, announced MLflow: an open source machine learning platform!
Documentation is located here.
On 06/05/2018 they announced this on their blog and 3 days later today, there are already 1,596 stars on github
Quick starts
# ensure I have pipenv to create virtualenv
$ pip3 install pipenv --user
# install mlflow
$ pipenv install mlflow
# activate mlflow environment
$ pipenv shell
# run test experiment
$ git clone https://github.com/databricks/mlflow.git
$ python mlflow/example/quickstart/test.py
# start UI
$ mlflow ui -h 0.0.0.0
# then you should see the test experiment
It consists of 3 components:
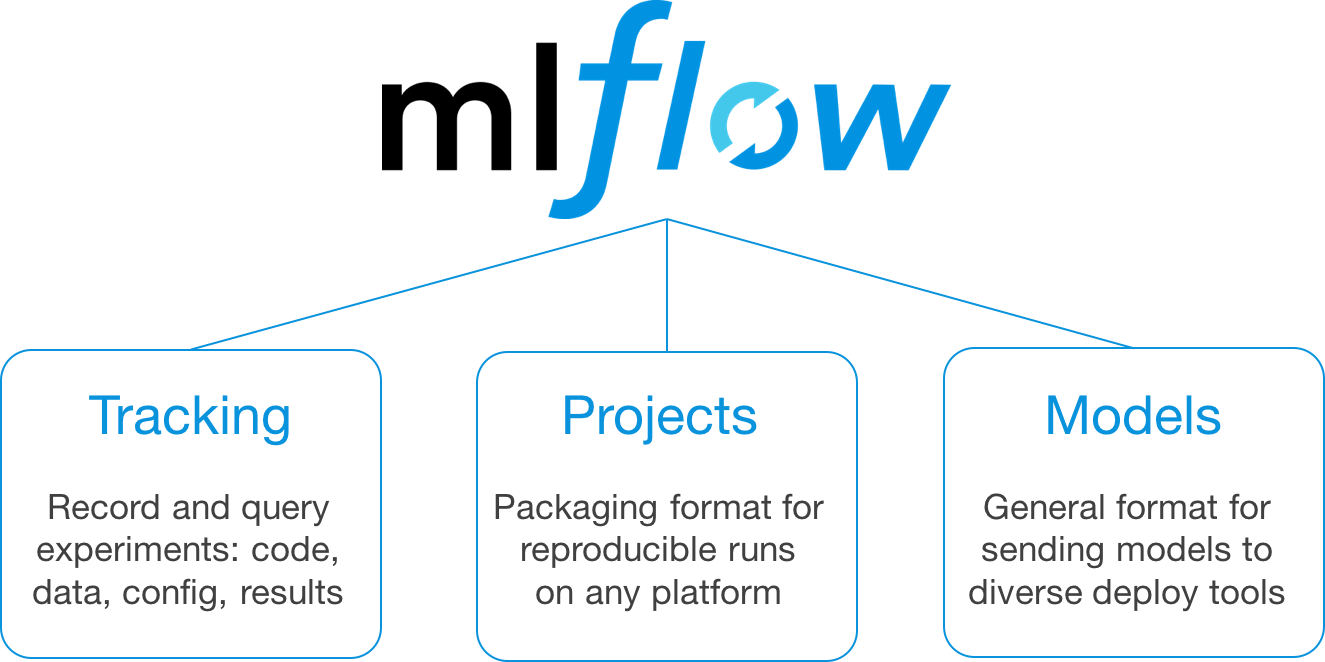
- Tracking: For querying and recording data on experiments. Using the web UI, you can view and compare the output of multiple runs.
- Projects: Provides a simple format for reproducing code
- Models: For managing and deploying models into production
Would be nice to have data components to do (a) Analysis (b) Transformation (c) Validation but I want to watch / evaluate and see how this grows!
Also I should compare other available tools such as Amazon SageMaker and IDSIA sacred
More reporting to come.
Cheers!